

【エクセル・マクロ】VBAで指定URLのHTMLタグをまとめて取得する
制作系案件ブログ第2弾の今回は、指定したWEBページ内のHTMLタグを自動で取得(スクレイピング)するプログラムを紹介します。
ページ上に複数ある指定タグを一覧として取得し、エクセルに書き出すことが可能です!
ブログや記事を新たに作成しようと思ったとき、検索上位にいる他のサイトのタイトルや見出しを比較・参考にしようと思ったことはありませんか?
今回はそんな時、まとめて確認出来るプログラム(VBA)を紹介したいと思います。
スクレイピングの流れ
今回はWEBページを開いてスクレイピングをするので
- InternetExplorer(以下:IE)で、確認したいページを開く
- ページ内の全指定タグを確認
- 指定タグの文字列を一覧として取得・保存
という流れになります。
サンプルの使い方
- 上記リンクからZIPファイルをダンロードして解凍します。
- エクセル(scraping.xlsm)を開きます。
- マクロを有効にします。
- 「取得ページ URL」を記入します。(必須)
- スクレイピングしたいWEBページのURLを指定します。
- 複数URLを指定する場合は、改行区切にします。
- ※ 認証や、ログインが必要なページは取得出来ません。
- 「取得タグ」を記入します。(必須)
- 取得したいHTMLタグ名を指定します。
- 複数タグを指定する場合は、改行区切にします。
- 「取得」ボタンを押下します。
- IEが立ち上がり、タグを取得します。
- IEが閉じ、完了を伝えるメッセージボックスが表示されます。
- 「Sheet2」にテキストが取得されていれば完了です。
4.5.
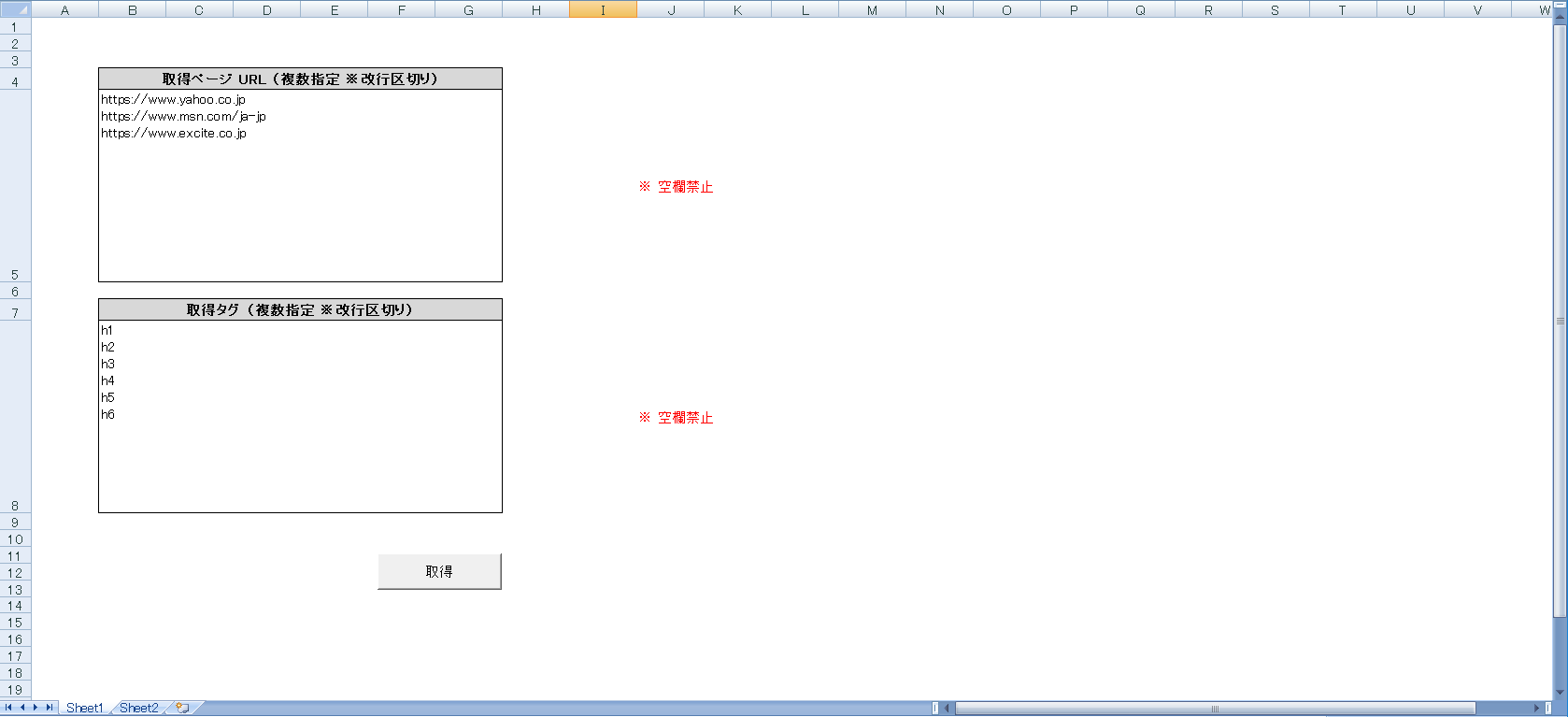
取得したいURL、HTMLタグを記入します。
8.
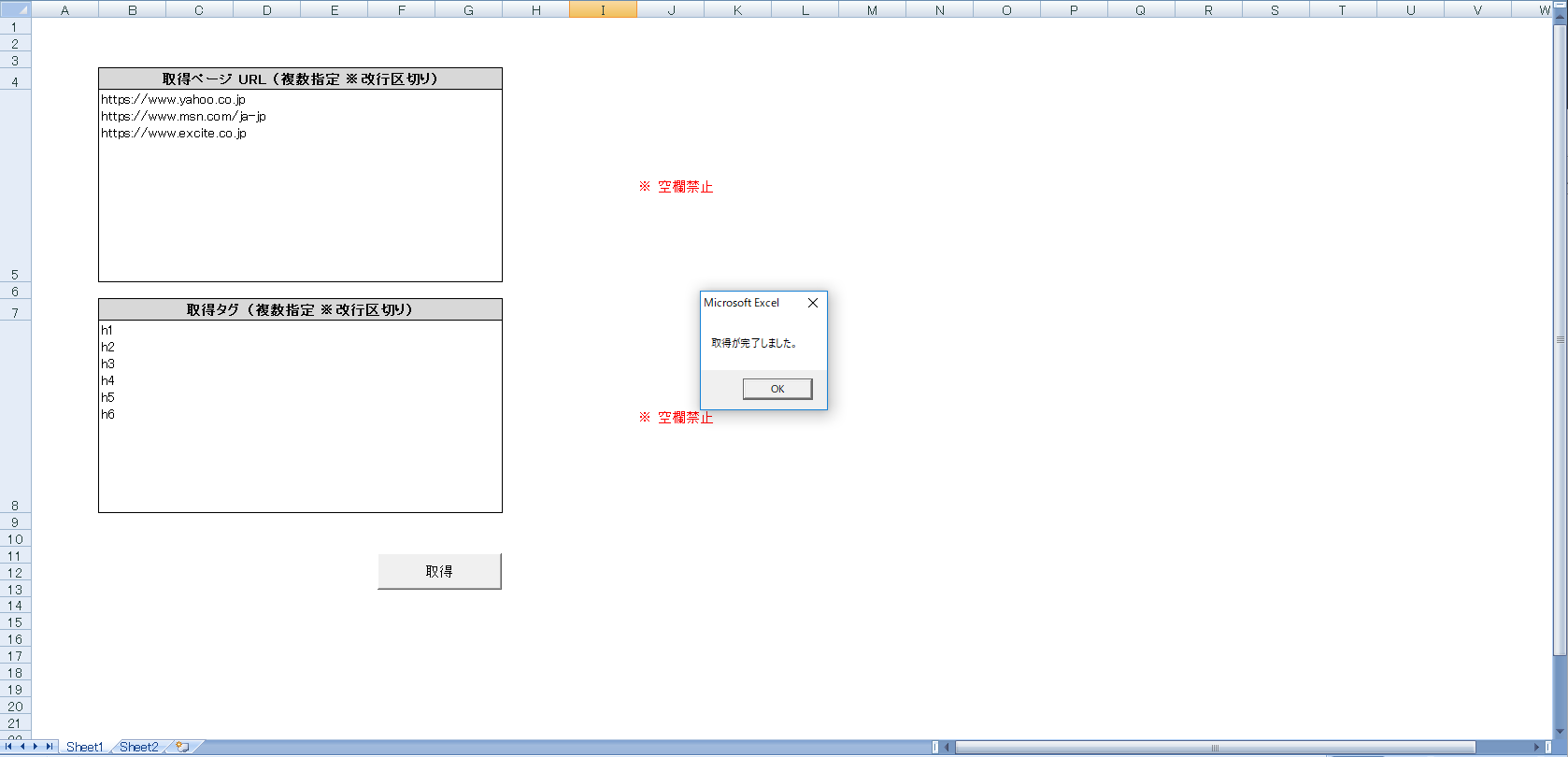
完了のメッセージBOXが表示されます。
9.
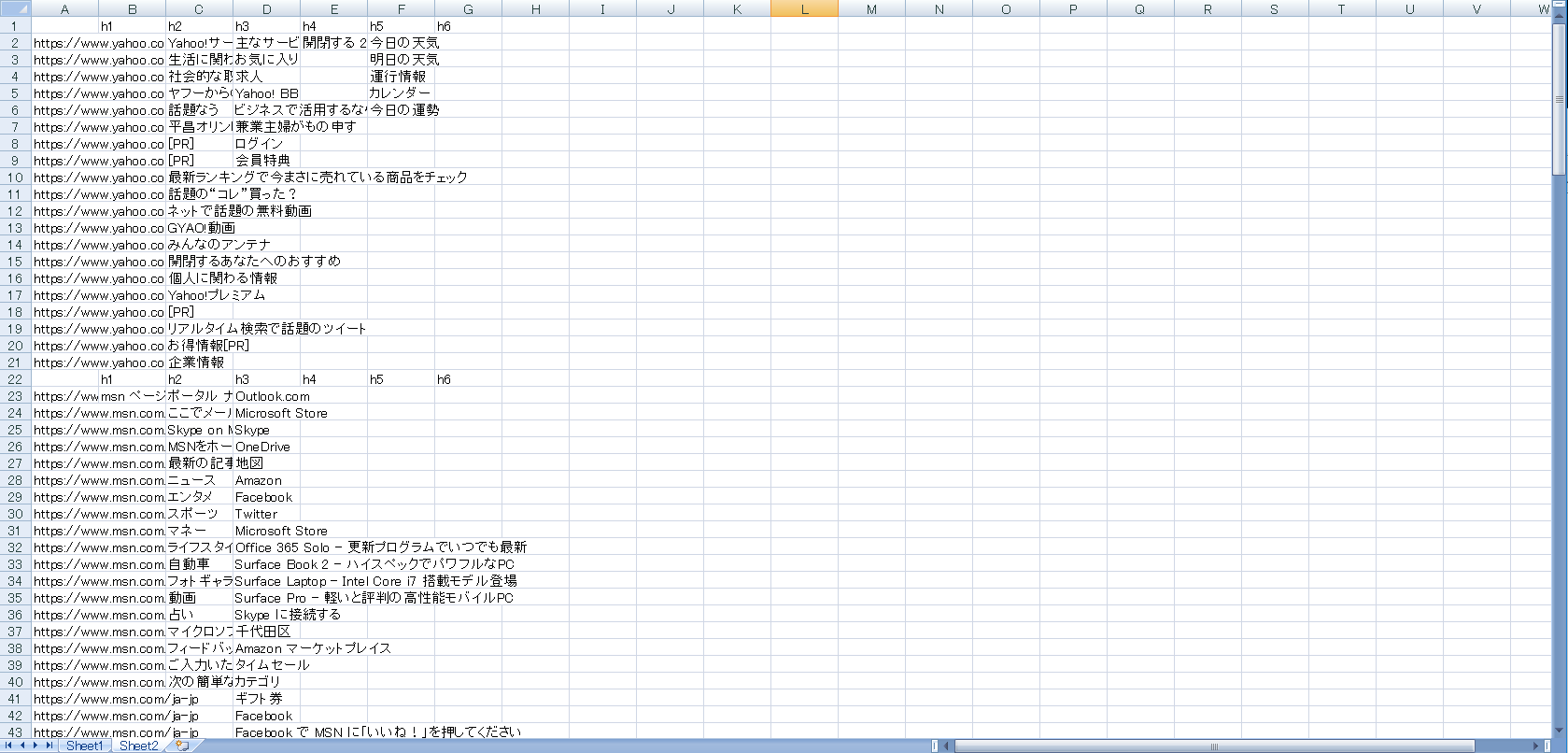
「Sheet2」にスクレイピングの結果が記入されます。
サンプルプログラムの説明
動作確認環境
- Windows10
- Excel2007
- InternetExplorer11
参照設定
今回はIEを生成し、DOM操作を行い、HTMLから値を取得するので以下の参照設定を追加します。
デフォルト参照設定
- Visual Basic For Applications
- Microsoft Excel **.* Object Library
- OLE Automation
- Microsoft Office **.* Object Library
追加参照設定
- Microsoft HTML Object Library
- Microsoft Innternet Controls
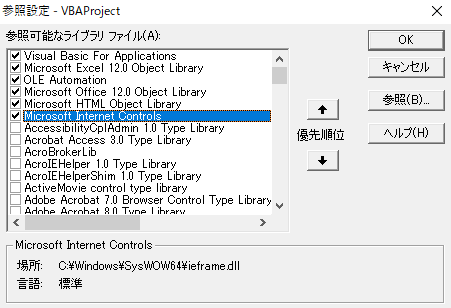
2つの参照にチェックを入れ「OK」を押すと参照が追加されます。
サンプル
サンプルファイルのダウンロード
header モジュール
Option Explicit
''' Sleep
#If VBA7 Then
Public Declare PtrSafe Sub Sleep Lib "kernel32" (ByVal dwMilliseconds As LongPtr)
#Else
Public Declare Sub Sleep Lib "kernel32" (ByVal dwMilliseconds As Long)
#End Iffunctions モジュール
Option Explicit
'''
''' スペース タブ 改行 削除
''' @param 対象 文字列
''' @retrun 削除後 文字列
'''
Public Function trimAll(str_ As String)
trimAll = Replace(Replace(Replace(Replace(Trim(str_), vbCrLf, ""), vbCr, ""), vbLf, ""), vbTab, "")
End Functionscraping モジュール
''' 参照追加
''' Microsoft HTML Object Library
''' Microsoft Innternet Controls
'''
Option Explicit
'''
''' scraping
'''
Sub main()
'
' WS 設定値
'
Dim str_urls As String
Dim str_tags As String
' WS 設定取得
With Worksheets("Sheet1")
str_urls = .Range("B5").Value
str_tags = .Range("B8").Value
End With
' WS 設定確認
If "" = str_urls Then
MsgBox ("取得ページURLを入力してください。")
Exit Sub
End If
If "" = str_tags Then
MsgBox ("取得タグを入力してください。")
Exit Sub
End If
' 記入済データ 消去
Sheets("Sheet2").Cells.Clear
'
' 処理開始
'
Dim urls
Dim tags
Dim url_length As Integer
Dim tag_length As Integer
Dim i As Integer, j As Integer
Dim ie As InternetExplorer
Dim tag As HTMLHtmlElement
Dim datas() As String
Dim counter_tag As Integer
Dim counter_max As Integer
Dim result
Dim row As Integer
row = 1
urls = Split(str_urls, vbLf)
tags = Split(str_tags, vbLf)
url_length = UBound(urls)
tag_length = UBound(tags)
' IE 生成
Set ie = CreateObject("InternetExplorer.Application")
With ie
' IE 可視化
.Visible = True
' URLの数だけ繰り返し
For i = 0 To url_length
' IE 取得用URL
.navigate urls(i)
' IE ページ表示待機
Sleep 1000
Do
Sleep 300
DoEvents
Loop Until (Not .Busy) And (.readyState = 4)
Sleep 1000
' 初期化
counter_max = 0
ReDim datas(tag_length + 1, 0)
' タグの数だけ繰り返し
For j = 0 To tag_length
counter_tag = 0
' header行 タグ名表示
datas(j + 1, counter_tag) = tags(j)
' ページ内 全指定タグ取得
For Each tag In .document.getElementsByTagName(tags(j))
' 二次元配列が足りない場合 追加
If counter_max < counter_tag + 1 Then
ReDim Preserve datas(tag_length + 1, counter_tag + 1)
End If
datas(j + 1, counter_tag + 1) = trimAll(tag.innerText)
counter_tag = counter_tag + 1
Next tag
' 最大二次元配列数 記憶
If counter_max < counter_tag Then
counter_max = counter_tag
End If
Next j
' 1列目に 取得URL 記入
For j = 1 To counter_max
datas(0, j) = urls(i)
Next j
' 取得データ まとめて書き込み
result = WorksheetFunction.Transpose(datas)
With Worksheets("Sheet2")
.Range(.Cells(row, 1), .Cells(row + counter_max, tag_length + 2)) = result
End With
' 次 URL開始 位置 + 1
row = row + counter_max + 1
Next i
.Quit
End With
Set ie = Nothing
MsgBox ("取得が完了しました。")
' Sheet2 表示
Worksheets("Sheet2").Activate
End Subプログラムの説明
header モジュール
''' Sleep
#If VBA7 Then
Public Declare PtrSafe Sub Sleep Lib "kernel32" (ByVal ms As LongPtr)
#Else
Declare Sub Sleep Lib "kernel32" (ByVal ms As Long)
#End If| ms | 待機したい時間(ミリ秒) |
|---|
「Sleep」は、「待機したい時間」を指定して、指定した時間だけ処理を待機するWindwosAPIです。
32bit、64bit、それぞれに対応出来るようAPIを分岐して宣言しています。
functions モジュール
'''
''' スペース タブ 改行 削除
''' @param 対象 文字列
''' @retrun 削除後 文字列
'''
Public Function trimAll(str_ As String)
trimAll = Replace(Replace(Replace(Replace(Trim(str_), vbCrLf, ""), vbCr, ""), vbLf, ""), vbTab, "")
End Function| str_ | 文字列 |
|---|
半角スペースを取り除く「Trim」の拡張版です。
半角スペースの他に、改行、タブも取り除きます。
戻り値は、それぞれを取り除いた文字列となります。
scraping モジュール
' WS 設定取得
With Worksheets("Sheet1")
str_urls = .Range("B5").Value
str_tags = .Range("B8").Value
End With
' WS 設定確認
If "" = str_urls Then
MsgBox ("取得ページURLを入力してください。")
Exit Sub
End If
If "" = str_tags Then
MsgBox ("取得タグを入力してください。")
Exit Sub
End If「取得ページ URL」は空欄禁止。
「取得タグ」は空欄禁止。
それぞれ複数指定の際は、改行区切り。
' 記入済データ 消去
Sheets("Sheet2").Cells.Clear' IE 生成
Set ie = CreateObject("InternetExplorer.Application")
With ie
' IE 可視化
.Visible = True
' URLの数だけ繰り返し
For i = 0 To url_length
' IE 取得用URL
.navigate urls(i)' 初期化
counter_max = 0
ReDim datas(tag_length + 1, 0)' タグの数だけ繰り返し
For j = 0 To tag_length' header行 タグ名表示
datas(j + 1, counter_tag) = tags(j)' ページ内 全指定タグ取得
For Each tag In .document.getElementsByTagName(tags(j))
' 二次元配列が足りない場合 追加
If counter_max < counter_tag + 1 Then
ReDim Preserve datas(tag_length + 1, counter_tag + 1)
End If
datas(j + 1, counter_tag + 1) = trimAll(tag.innerText)
counter_tag = counter_tag + 1
Next tagタグ数が不定な為、ReDim Preserveで、配列数を拡張しながら、テキストを格納していきます。
改行、スペースなどがあるとテキストを確認し難いので、予め宣言しておいたtrimAllで、余分なものを取り除きます。
' 1列目に 取得URL 記入
For j = 1 To counter_max
datas(0, j) = urls(i)
Next j' 取得データ まとめて書き込み
result = WorksheetFunction.Transpose(datas)
With Worksheets("Sheet2")
.Range(.Cells(row, 1), .Cells(row + counter_max, tag_length + 2)) = result
End WithSheet2に、まとめて貼り付けます。
' Sheet2 表示
Worksheets("Sheet2").Activateまとめ
サンプルファイルのダウンロード
今回は指定URLから指定タグのテキストを抜き出す方法について、サンプルをもとに解説しました。
今回のサンプルでは、IEを生成してからタグを取得しましたが、「WinHttpRequest」などで取得したレスポンスから、指定タグを取得すれば、IEを開く手間と時間が省略出来ます。
また、今回はページ毎で、セルに張り付けていきましたが、全てのページのデータを取得してから、セルに張り付ければ時間の短縮になると思います。
※ サイトによってスクレイピングを禁止している場合がありますので、ご注意ください。
※ 取得したテキストを無許可で公開してしまうと著作権に触れる可能性があるのでご注意ください。
※ 本プログラムを利用しために被る損害について、当社に故意または重大な過失がある場合を除き、当社は一切その責任を負いません。
まだ仕様の決まっていない場合のご相談などもお気軽にご相談ください。
